Gitlet之我见
CS61B—Gitlet 之我见
CS61B 的课程项目有一大特点,便是循序渐进——当我刚刚接受完 Java 基本语法的熏陶之时,Project1 的双端队列于我而言尚有一定难度。在文档中求索,在代码中前行。磕磕绊绊写完 proj1 的时候,鼠鼠内心不由得感到一丝恐慌——听说后面的 Gitlet 是个不得了的大家伙,而这先锋兵将 proj1 已让我汗流浃背(事后诸葛亮来看,应该是 Java 速通太快的缘故)!怀揣着这样忐忑又略显激动的心情,在扎扎实实啃完所有课程以及 lab 之后,我敲开了 Gitlet 的大门——
站在已经写完 Gitlet 的视角来看,它的特点并不是难度高,而是文档冗长以及开发要求众多。2W 字的文档足以好好磨砺你的英文阅读能力。(或许这就是贴近实际开发过程的体现么,hhh)最后加上 EC 部分,总计用时大概是 25h,不算 EC 是 19h,如下:
(这段时间在学球,所以战线拉得很长,大概每天只能写 2-3h。有时候教练不在,狂写一天,爽哉)
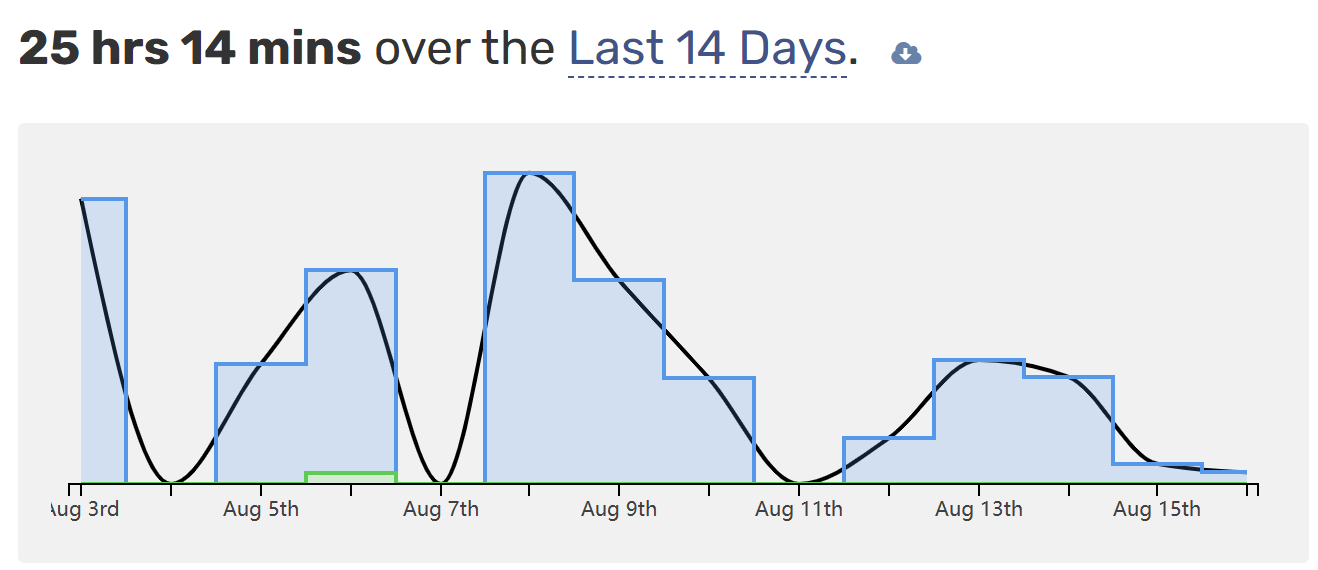
我自己的实现:Gitlet
证明我写完了 EC:

下面是我自己的一些总结,建议,部分命令的思路以及它带给我的收获:
对后来人的建议
- 在开始写代码之前,尽量看完整个项目文档,在脑海中有一个大致完整的构思框架。这样可以避免一直写一直改之前的窘境,甚至会面临全部推倒重写!
- 良好的代码规范!给所有变量命名必须讲究到位,增加代码可读性,不然睡一觉起来就不知道自己干了啥了
- 多多写注释!这并不是浪费时间的习惯,相反,到位明了的注释在你 debug 时将会有良好的引导功能。很多时候我们的 bug 并不是大的逻辑有问题,而是就是在小的地方出了谬误,例如条件判断时的”!”,忘记一些必备基础操作等等,这种 bug 才是最难 de 的!
- Commit,Blob,Stage,Branch,Remote这些基础概念务必理解到位,**/.gitlet**仓库的结构务必安排好!
- Utils 里的辅助方法不是一成不变的,你可以自己加一些有助于自己开发的函数进去!
Bug 重灾区&&小技巧
- 忘记保存文件
- 忘记修改 HEAD
- 忘记调整 BRANCH
- 忘记 add 文件到 Stage
- 生成 id 的时候不考虑实际因素(卖个关子)
- 忘记 Java 中对象指针值传递的本质(即浅拷贝)
- EC 时忘记修改 CWD
- 新建文件和目录可以在 Utils 里新加函数,避免反复写 try-catch
- Commit 的时间戳需要修改格式,记得写辅助方法
- EC 后你的 branches 文件夹可能包含子文件夹,这时候可以修改那个读文件的辅助函数,保证 status 命令不会寄
- 代码复用,事实上 reset,fetch,push,pull 这四个命令几乎不需要怎么写,逻辑写出来,然后发现可以代码复用,就问你爽不爽吧。这也是之前说要考虑清楚再
动笔开始写代码的原因所在
总体思路
/.gitlet 仓库安排
根据文档要求,gitlet 只处理平面文件夹里面的内容,不考虑递归处理子文件夹,那么可以讲 Blob 和 Commit 直接“平摊”存储在对应文件夹下。Stage,Branch,Remote 分别存储在对应目录。这样的安排或许不是最佳,但是思路理解上还是较为中规中矩的,不是太难。
1 | |
其中 HEAD 和 BRANCH 是储存当前提交 id 和分支 name 的文件,随用随取,随取随读,随读随改,随改随存
类的分配
我特别喜欢写类,某种意义上写一个好的类也是代码复用的体现所在,所以有的地方或许可以用一个列表直接拉过去,但是我还是写了相应的类便于理解操作
Main:主程序所在地,处理输入命令参数Repository:大部分代码所在地,实际编写处理命令的方法的地方Commit:提交的类,包含 id,文件路径与 BlobId 的映射,Blob 的列表,Message,TimeBlob:文件的类,包含文件名字,内容,idStage:缓存区的类,直接一个 BlobId 和文件路径的映射就完事,再编写一些辅助方法Branch:分支的类,包含分支名以及存储的 CommitIdRemote:远程的类,这个类其实可以不要的,但是我强迫症上来了()。包含远程名字和仓库路径
Persistence
对所有需要持久化的类写一个saveToFile()方法就完事,别忘了用就行
(不会有人还没写 Lab 6 吧,不会吧不会吧)
必做部分命令思路
太简单的就不写了罢……
init
虽然说测试中只检测了你的/.gitlet 目录,但是还是有更多工作要做,按照文档一步步来
检测文件夹是否存在,存在就退出
创建一个新的分支 master,这也是初始默认分支
创建初始提交,让 master 指向它
创建各级目录
创建两个空的缓存区
你会发现有的东西涉及到后面的命令,这时候可以把写不了的部分打一个 TODO,后面来补
推荐用时:1-2h,加上理解以及写各类可能会到 4h
后面的每个命令都需要检查文件夹是否存在了,不能不存在
add
虽然说只需要将对应文件添加到缓存区,但是仍然要考虑其他的情况
- 先检查该检查的
- 如果文件在 removeStage 里,移出(涉及到 rm 命令,可以留白)
- 创建新的 Blob(这些对应的类你应该已经写好十之八九了)
- 添加到 addStage
- 不要忘了保存
推荐用时:1h
commit
第一个坎,建议写了 rm 后再来写,因为 rm 可以看作是 add 的逆命令,而 commit 和这两个都有关系
- 构造函数可以写两个,一个用于普通 commit,一个是初始 commit 专用
- id 生成记得用
toString()一下类里的其他成员 - 先检查
- 生成新的 commit,这时候它的内容除了时间和它的 parent 是一样的
- 根据两个 stage 修改内容
- 修改 HEAD 与当前分支的内容
- 保存
推荐用时:2h
rm
有了写 add 的经验写这个应该比较快,注意分类讨论:
在 addStage 里,删除之
不在 addStage 里,但在当前 commit 里(即最新 commit),加入 removeStage,commit 的时候删除
是上面第二种情况的话,CWD 中不能存在该文件,即存在就删掉
推荐用时:1h
log && global-log
前者 DFS,后者直接用 plain 那啥的辅助函数
可以考虑给 Commit 类写一个
print()的辅助方法
find
这个简单,正式 git 都没有,考你对自己写的类的掌握情况呢
推荐用时:10min
status
这个分类有点多,最后两个还是 ec 的部分,一步一步来即可
- branch:直接读目录里的文件就行
- 两个 stage:把 stage 的文件读出来就行,也可为 Stage 类写一个
print()的辅助方法 - 修改未保存:按照文档分的四类一步步写即可,注意 blobId 即可代表两个文件是否相同
- 未跟踪:读 CWD 文件,一个一个判断即可
推荐用时:20min(无 EC),1h(含 EC)
checkout
三个类型一步步写,其实这里建议在两个 branch 命令之后写
- 检出文件:建议写一个辅助方法,后面会用到
- 检出某个 commit 里的某文件:同上
- 检出某个分支:再写一个辅助方法,完成这里这个命令的同时也为后面 reset 服务
推荐用时:4h(debug 麻了)
branch && rm-branch
虽然 branch 的概念很高大上,复杂,但是不妨碍这两个命令很简单啊!稍加思考即可发现:branch 功能本身的实现是在 merge,checkout 一系列命令的加持下才成型的。对于这两个命令,我们只需要做该做的事即可
- branch:创建这么一个对象,保存
- rm-branch:找到这个文件,删掉它
- 记得检查!
- 没了
建议用时:30min
reset
提示:用 checkout 的某类情况的辅助方法,实际上这个 reset 也是真实 git 的 checkout 的功能之一(但是不会头分离,最接近 reset –HARD)
建议用时:10min
merge
必做部分的最大 boss,推荐先观看视频,深入了解 merge 的对每个文件处理的八个情况分别是什么,再拟出自己的思路,一步一步写,并且随时 debug,这样可以减轻自己的痛苦时间()
我的总体思路如下:
- 检查
- 处理 easy cases
- 用 BFS 获取 splitCommit
- 现在手上有三个 commit:分裂点,待合并的 branch 指向点,当前点
- 获取其中所有文件,一一处理,这一步我的选择是返回一个 result 的 map,因为我还没检查,要检查后才能操作
- 检查 result 是否合法
- 检查完毕,根据 result 的指示处理文件(考虑用一个 flag 记录是否发生 conflict)
- 处理完毕,创建 merge commit
- 根据处理结果(两个 stage)修改 commit
- 保存之,若 conflict 则打印相关信息
- 清空缓存,设置 HEAD,BRANCH 文件,欢呼!
对于文件处理,牢 TA 的分类:

我来给它升个级:
- 对于每一个文件,它在 splitcommit,branchcommit,currentcommit 均有相应的形态(不存在也是形态之一)
- 若三者皆不相同,就是 conflict!
- 若三者皆相同——那讨论个毛线!
- 若两两相同,进一步分类:
- s 与另两个之一相同,保留第三者
- s 与另两个都不同,但另两个相同——保留 current 即可(即不做操作)
一下子就只有三类了,明了了许多对不对
推荐用时:6h,但是 debug 无上限(我自己就几个小 bug,比如忘记写!,忘记 add,却 debug 了五六个小时)
恭喜!1600 分到手!
选做部分命令思路
总体不难,因为有大量代码复用,注意规划好类与文件夹分区即可
总体思路:每个 remote 是一个对象,里面包含了 remote 的名字和远程仓库路径。编写一个改变当前 CWD 的辅助函数用于操作 fetch,push 与 pull。似曾相识的地方就代码复用,必要时小改之前的命令用于抽出辅助函数复用。
具体命令思路:
add-remote && rm-remote
类比 branch 那边,虽然 remote 是一个大的复杂的概念,但是这俩命令不难呀,按自己的思路写好就行,我的思路:
- add-remote:创建 remote 对象,保存(文档要求不用检查合法性)
- rm-remote:找到那个 remote 文件,删掉!(记得先检查这个 remote 是否存在)
推荐用时:30min
fetch
我的思路里,核心在于改变 CWD 以及复制 commit 和 blob 们(复制 commit 时我出了超级逆天爆冷大 bug,下面详谈)
fetch 的要求是将远程的分支拽过来但是不合并,合并是 pull 的事情,咱 fetch 不用管,自然有了如下思路:
- 检查文件夹以及参数是否合法
- 拿到远程分支,用 BFS 取到它的历史(代码复用 merge 的部分)
- 回到本地工作目录
- 开始复制!注意!复制的时候不能只傻傻地把文件拉过来,还要修改内部文件的路径(注意这里并不会影响 id 生成,思考这是如何实现的?),不然你后面 checkout 的时候有好果汁吃,就是这里吃掉我 2h 的 debug 时间
- 修改本地远程跟踪分支,若不存在则创建,注意文件名不能有/,所以我直接创建的子文件夹
- 上述过程中注意随时切换 CWD
推荐用时:3h
push
类比为 fetch 的反向特化版,因为它的条件要求更苛刻,并且复制那一部分的逻辑是一样的,思路如下:
- 先老规矩,检查
- BFS 获取本地分支历史(和上面不一样吧,但是直接美美复用)
- 检查远程分支是否存在
- 若是,获取那边的头部,检查是否在本地历史中
- 若否,直接进入下一步
- 向远程仓库复制 commit 和 blob
- 修改远程分支,不存在则创建,记得保存
- 没有啦
推荐用时:1h
pull
文档已经写好了:fetch + merge,两行代码搞定!
推荐用时:2 min 30 s (只因代码复用太美)
恭喜!完整版 Gitlet 已完成!
总结与收获
代码量的话,我的 repo 类是 1200 行,不算 ec 是 900 行。如果少啰嗦一点可以更节约
总体难度其实不大,主要是量确实大,以及起步很难,不愣个一天神是不行的
收获真的很大,最重要一点就是克服了之前就有的项目恐惧症——
- 总觉得 61A 的项目太小儿科,对自己的码力没有自信
- 面对大项目就发怵,心里没底
- 写了一堆代码后很害怕 debug,不知道它会藏在哪里暗杀我
除此之外便是一次完整的超级 mini 版的开发体验,用 git 做版本控制工具写 gitlet,真是奇妙的体验呀!
记录自身成长的同时,也希望能够帮助到你!谢谢!